
摘要:隨著人工智能技術的火熱,越來越多的年輕學者正準備投身其中,開啟自己的研究之路。 和所有其他學科一樣,人工智能領域的新人總會遇到各種各樣的難題,其中不僅有研究上的,也有生活方面的。 MIT
EECS在讀博士
隨著人工智能技術的火熱,越來越多的年輕學者正準備投身其中,開啟自己的研究之路。 和所有其他學科一樣,人工智能領域的新人總會遇到各種各樣的難題,其中不僅有研究上的,也有生活方面的。 MIT
EECS 在讀博士、前 Vicarious AI 員工 Tom Silver 近日的一篇文章或許對你有所幫助。
我的一個朋友最近正要開始人工智能的研究,他問及我在 AI 領域近兩年的研究中有哪些經驗教訓。 本文就將介紹這兩年來我所學到的經驗。 其內容涵蓋日常生活到 AI 領域中的一些小技巧,希望這可以給你帶來一些啟發。
開始
找到一個你感覺合適的人詢問「傻問題」
最初,我非常害怕自己的同事,羞於向人提問,因為這可能會使我看起來非常缺乏基礎知識。 我花了好幾個月才適應了環境,開始向同事提問,但一開始我的問題仍然非常謹慎。 不過現在,我已有三四個關係較好的人了,我真希望當時能早點找到他們! 我曾經淹沒在谷歌搜索的條目中。 現在,當我遇到一個問題後會直接詢問他人,而不是自己想辦法,最終陷入困惑。
在不同的地方尋找研究靈感
決定做哪些工作是研究過程中最困難的一部分。 對此,研究人員已經存在一些一般性的策略:
-
與不同領域的研究者交談。 問問他們對於哪些問題感興趣,並試圖用計算機專業的語言重述這些問題。 詢問他們是否有想要進行分析的數據集,哪些現有技術是解決問題的瓶頸。 機器學習中很多最具影響力的工作都是計算機科學與生物/化學/物理學、社會科學或者純數學之間的碰撞。 例如
Matthew Johnson 等人在 NIPS 2016 的論文《Composing graphical models with
neural networks for structured representations and fast
inference》是受到一個小鼠行為數據集啟發的結果;Justin Gilmer 等人在 ICML 2017 上的論文《Neural
Message Passing for Quantum Chemistry》應用於量子化學。 -
編寫一個簡單的基線來獲得對問題的感受。 例如,嘗試編寫一個有關控制倒立擺的詳細校準代碼(https://gym.openai.com/envs/Pendulum-v0/),或者試著看看能不能在自然語言數據集上推送一個詞袋模型 。 我在編寫基線時經常會遇到無法預料的情況——我的想法或代碼裡都有可能出現錯誤。 在基線運行時,我通常會對問題有更深的理解,並產生出很多新的想法。
-
擴展你喜歡的論文的實驗部分。 仔細閱讀方法與結果,嘗試找到問題的關鍵。 首先嘗試最簡單的擴展,問問自己:論文中的方法是否適用,思考一下文中沒有討論的基線方法,以及它們可能會失敗的原因。
投資可視化工具和技能
在編寫研究代碼時我採用的策略是從創建可視化腳本入手。 在編寫完其餘代碼後,我會運行可視化腳本,以快速驗證代碼是否與我的心智模型匹配。 更重要的是,良好的可視化經常會使我想法或代碼中的
bug 更加明顯、明了。 這裡還有一些自我激勵的話要說:當我完成這個代碼時,我會做一份漂亮的數據或視頻給大家看!
為手頭的問題尋找合適的可視化方法可能非常棘手。 如果要迭代優化模型(例如深度學習),從繪製損失函數曲線著手會比較好。 此外還有許多用於可視化和解釋神經網絡(特別是卷積神經網絡)學得權重的技術,例如導向反向傳播。 在強化學習和規劃中,智能體在其環境中的行為是顯而易見的,無論是雅達利遊戲、機器人任務還是簡單的
grid world(如 OpenAI Gym
中的環境)。 根據設置,還可以可視化價值函數及其在訓練過程中的變化(如下所示),或者可視化探索狀態樹。 在處理圖形模型過程中,當一維或二維變量在推斷過程中發生變化時,對其分佈進行可視化可以獲得豐富的信息(如下所示)。 估計每次可視化分析時必須在頭腦中保存的信息量可以幫助檢測可視化技術的有效性。 如果可視化技術非常糟糕,你需要詳盡地調用你編寫的代碼來生成它;反之,一個良好的可視化技術可以帶來一個明顯的結論。

Tensorboard 是可視化 TensorFlow 深度學習模型的常用 GUI。
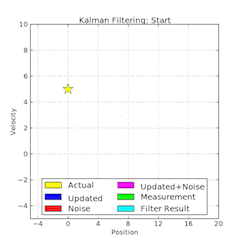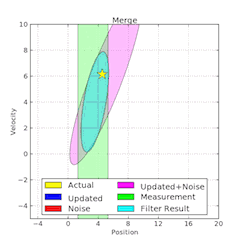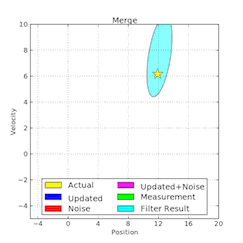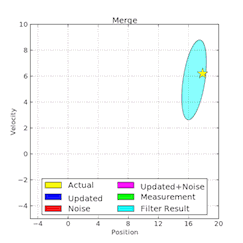
隨著數據的積累繪製分佈圖可以大大降低 debug 圖形模型的難度(來自 Wikimedia)。
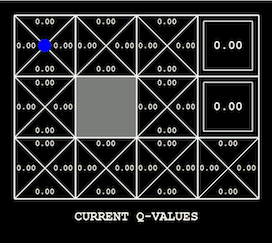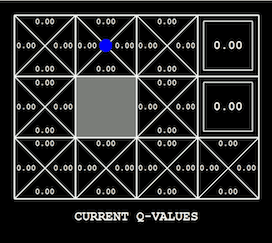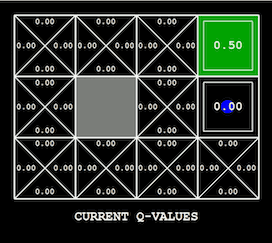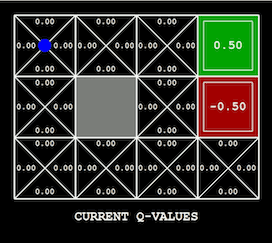
用 Q-learning 學習的價值函數可以在它所表示的 grid world 上可視化(作者:Andy Zeng)。
確定研究人員和論文的基本動機
在相同的會議上發表文章、使用相同的技術術語、自稱研究領域是人工智能的研究人員可能有截然相反的研究動機。 一些人甚至建議為這個領域取不同的名字,以澄清問題(就像Michael
Jordan 在最近一篇優秀的博客文章中提到的那樣)。 他們的動機至少可分為三類:「數學」、「工程」和「認知」。
-
「數學」動機:智能係統有何基本屬性和局限性?
-
「工程」動機:如何開發能夠更好地解決實際問題的智能係統?
-
「認知」動機:怎樣才能模仿人類和其他動物的自然智能?
這些動機可以和諧共存,許多人工智能領域的有趣論文都是從多個角度出發。 此外,單個研究人員的研究動機往往並不單一,這有助於實現人工智能領域的聚合。
然而,動機也可能並不一致。 我有一些朋友和同事,他們有明顯的「工程」傾向,還有一些主要對「生物學」感興趣。 一篇論文表明,現有技術的巧妙結合足以在基准上超越現有技術水平,這將激起工程師們的興趣,但認知科學家可能對此不感興趣,甚至嗤之以鼻。 但如果一篇論文闡釋了生物可解釋性(biological
plausibility)或認知聯繫,這篇論文收到的反響可能截然相反,即使其結論只是理論性的或結果非常不起眼。
優秀的論文和研究人員在一開始就會說明他們的動機,但根本動機往往藏地很深。 我發現在動機不明顯的情況下,對論文進行各個擊破將會很有幫助。
從科研社區中汲取營養
找論文
AI
領域的論文可以在 arXiv 上找到和發布。 現在的論文數量非常令人振奮。 社區中的許多人降低了從噪聲中分辨出信號的難度。 Andrej
Karpathy 開發了 arXiv sanity preserver,幫助分類、搜索和過濾特徵。 Miles Brundage
每晚都在推特上發布自己整理的 arXiv 論文列表。 很多推特用戶常常分享有趣的參考文章,我推薦大家在推特上關注自己喜歡的研究者。 如果你喜歡用
Reddit,那麼
r/MachineLearning(https://www.reddit.com/r/MachineLearning/)非常棒,不過文章更適合機器學習從業者而不是學界研究者。 Jack
Clark 發布每週社區 newsletter「Import AI (https://jack-clark.net/)」,Denny
Britz 發布「The Wild Week in AI (https://www.getrevue.co/profile/wildml)」。
查看會議論文集也很值得。 三大會議是
NIPS、ICML、ICLR。 其他會議還包括 AAAI、IJCAI、UAI。 每個分支學科也有自己的會議。 計算機視覺方面有
CVPR、ECCV、ICCV;自然語言方面,有 ACL、EMNLP、NAACL;機器人方面,有
CoRL(學習)、ICAPS(規劃,包括但不限於機器人)、ICRA、IROS、RSS;對於更理論性的研究,有
AISTATS、COLT、KDD。 會議是目前論文發表的主要渠道,但是也有一些期刊。 JAIR 和 JMLR
是該領域最厲害的兩種期刊。 偶爾一些論文也會出現在科學期刊上,如 Nature 和 Science。
尋找舊的論文同樣重要,不過通常更難。 那些「經典」論文通常出現在參考文獻中,或者研究生課程的閱讀書單。 發現舊論文的另一種方式是從該領域的資深教授開始,尋找他們的早期作品,即他們的研究路徑。 同樣也可以向這些教授發送郵件詢問額外的參考(即使他們太忙沒有回復也不要介意)。 尋找不那麼有名或被忽視的舊論文的一種持續方式是在
Google scholar 中搜索關鍵詞。
應該花費多長時間閱讀論文?
關於閱讀論文應該用的時間我聽到過兩種常見建議。 一,剛開始的時候,閱讀所有論文! 人們通常說研究生的第一學期或第一年應該只閱讀論文。 第二,在最初的上升期之後,不要花費太多時間閱讀論文! 原因在於如果研究者不被之前的方法左右,更有可能創造性地提出和解決問題。
我個人同意第一條建議,不同意第二條。 我認為一個人應該盡可能多地閱讀論文。 「如果我不熟悉別人嘗試過的方法,那我就能更好地想出新穎的更好方法。」——這種想法似乎不太可能,且傲慢。 是的,新視角可能是一把鑰匙,業餘者解決長期挑戰是因為他們超出常規的想法。 但是職業研究者不能完全依賴運氣來探索未被考慮過的解決方案。 我們的大部分時間都用來緩慢且有方法地逐步解決問題。 閱讀相關論文是找出我們所處位置和下一步嘗試方向的更高效方式。
關於盡可能多地閱讀論文,有一個重要的注意事項:消化論文內容和閱讀論文一樣重要。 用一天時間學習幾篇論文、認真做筆記、認真思考每一篇的內容和思路,比不斷閱讀論文要好一些。 盡可能多地閱讀論文。
對話 >> 視頻 > 論文 > 會議演講
論文絕對是了解陌生研究思路的最易獲取的資源。 但是最高效的路徑是什麼呢? 不同人的答案或許也不同。 我認為,對話(和已經理解該思路的人對話)是目前最快、最有效的路徑。 如果這種方法不可行,那麼相關視頻也會提供很好的見解,比如論文作者受邀進行演講。 當演講者面對的是現場觀眾時,他們可能更偏重清晰性而不是準確度。 而在論文寫作中,這種偏重是相反的,字數統計是關鍵,背景解釋可能被當作作者不熟悉該領域的證據。 最後,簡短的會議演講通常更正式,而不是合適的教育機會。 當然,演講結束後與演講者進行對話交流是非常有價值的。
小心炒作
成功的人工智能研究總會引起公眾的關注,讓更多的人進入這一領域,從而引出更多成功的
AI
研究。 這一正循環在大部分情況下都是適用的,但其也有一個副作用就是炒作效應。 新聞編輯總是希望獲得更多點擊率,科技公司則希望獲得投資者的青睞,並多多招募新人,而研究者們往往會追求高引用量和更高質量的發表。 在看到一篇文章或論文的標題時,請務必注意這些問題。
在
NIPS 2017
的一個論文討論活動中,數百名聽眾目睹了一位有名望的教授拿著麥克風(「我謹代表炒作警察」)勸告作者不要把單詞「imagination」用在論文標題中。 我對於這種公眾對抗總是有著複雜的感受,而且我還恰好喜歡這篇論文。 但這並不意味著我無法理解這位教授的挫敗感。 人工智能研究中最常見,最令人厭惡的宣傳表現之一,就是用新術語重新命名舊概念。 所以,小心那些流行語——主要根據實驗及其結果來判斷一篇論文。
開始科研馬拉松
樹立可衡量的進展目標
之前搜尋研究項目時,我花費了大量時間進行頭腦風暴。 那時對我來說,頭腦風暴就是把腦袋擱在桌子上,希望一些模糊的直覺可以變成具體的見解。 結束了一天的「頭腦風暴」,我常常感覺疲憊、灰心喪氣。 這是科研嗎? 我很疑惑。
當然,沒有導向科研進展的良方,在黑暗中瞎撞是(大部分)進展的一部分。 但是,現在我發現樹立一個可衡量的目標,然後計劃工作,更加容易且易於實現。 如果我不知道接下來要做什麼,那麼目標可以是:寫下一個模糊的想法,但要盡可能詳細;如果在寫的過程中,覺得這個想法不好,那就寫出排除該想法的理由 (而不是完全廢除這個想法,這樣就失去了對進展的衡量)。 在沒有任何想法的時候,我們可以用讀論文或與同事交流的方式取得進展。 一天結束時,我的工作有了一些實實在在的東西。 即使這些想法永遠不會用到,但是我的鬥志得到提升,也不再擔心以後會在相同的想法上浪費時間。
學會判斷死胡同,並退回來
強大的研究者花費更多時間在好的想法上,因為他們在糟糕想法上所用的時間較少。 能夠識別好想法和壞想法似乎很大程度上是經驗問題。 然而,任何水平的研究者都會經常遇到下面的決策問題。 我的研究思路有缺陷或無法產生結論,我應該嘗試
A)繼續挽救或支持這個思路,還是 B)完全拋棄這個思路呢? 我個人非常後悔在本應該做 B)時卻把時間浪費在
A)上。 尤其是之前,我曾多次陷在死胡同中,而且時間很長。 我之所以不願意離開很大程度上是由於沉沒成本誤區:如果我退出這個「死胡同」,那我已經花費的時間不就白白浪費了嗎?
現在當我離開研究死胡同時還是會感到一些失望。 不過我現在嘗試使自己意識到後退也是一種進步。 成本花費得值,不算沉沒。 如果我今天沒有探索死胡同,那我可能明天還會遇到。 死胡同並不是終點,它們是科研生活的一部分。 希望我能堅持這種想法,如果不能,還有費曼的名言呢:我們嘗試盡快證明自己是錯誤的,只有這樣我們才能進步。 (We
are trying to prove ourselves wrong as quickly as possible, because
only in that way can we find progress.)
寫!
我曾經偶然諮詢過一位傑出的 AI 研究者早期職業生涯忠告。 他的建議非常簡單:寫! 寫博客和論文,以及更重要的,寫下一天當中自己的想法。 我開始注意到積極地寫下想法與只是想想帶來的明顯差別。
身心健康是科研的先決條件
有一種錯誤的觀點認為科研工作者都是廢寢忘食,一心追尋科學發現。 我之前以此為基準,常常為無法做到而感到內疚。 現在我知道鍛煉和精神放鬆是投資,而不是乾擾。 如果我每天睡
8 小時,工作 4 小時,我的效率比睡 4 小時、工作 8 小時要高得多,也就是說沒有造成不好的影響。
在解決一個困難的問題時中途停止是非常困難的。 我仍然會一直研究一個問題,即使已經非常累了,即使沒有進展也不休息。 當停下來深呼吸時,我會非常高興。 我希望在科研生涯的下一個階段能夠繼續內化這件事。
版權聲明
本文僅代表作者觀點,不代表百度立場。
本文係作者授權百度百家發表,未經許可,不得轉載。